TOPPO: Rethinking PPO for Multi-Task Reinforcement Learning with Critic Balancing
Rui Miao
Department of Mathematical Sciences
Texas AI Research Institute
University of Texas at Dallas

Meta-World (MT50, https://meta-world.github.io/)
Why the worst-\(k\) tasks matter
A high mean can hide tasks that never become reliable. In a pipeline of skills, the weakest stages set the usable system reliability.
Official Meta-World broad-suite GIF. MT50 trains one task-aware policy on all 50 tasks; the official site does not provide a separate MT50 GIF.
The critic is where PPO breaks
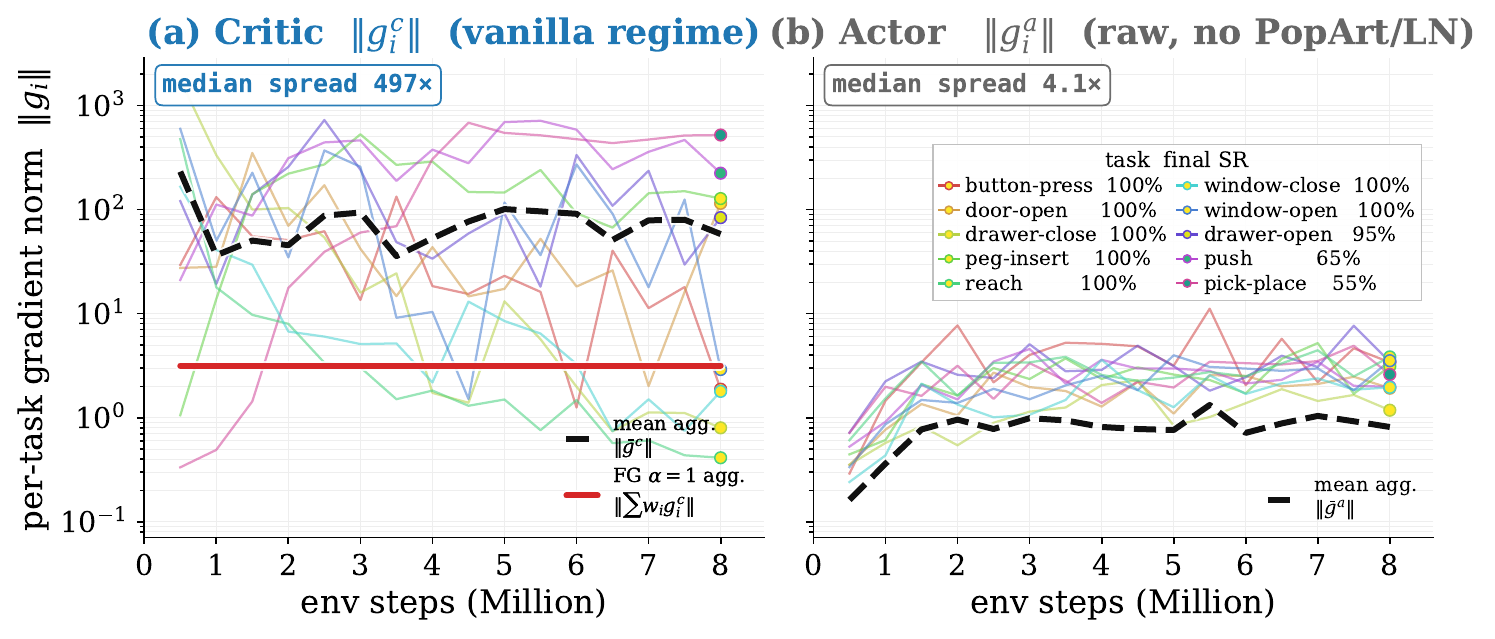
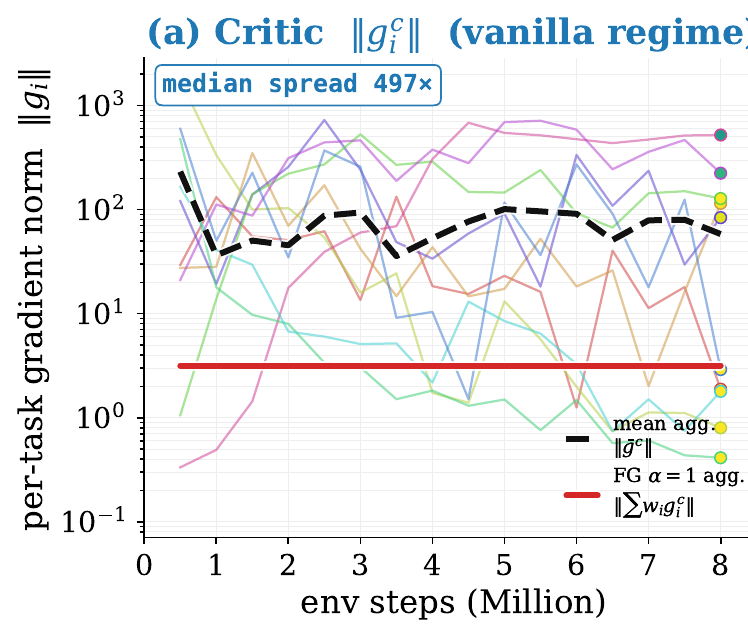
critic gradient norm spread
actor spread after task-wise advantage normalization
The intervention target is not PPO as a whole. It is the shared critic update.
PopArt normalizes value targets before gradients form
PopArt standardizes each task's return targets, while reparameterizing the affine head so raw predictions do not jump.
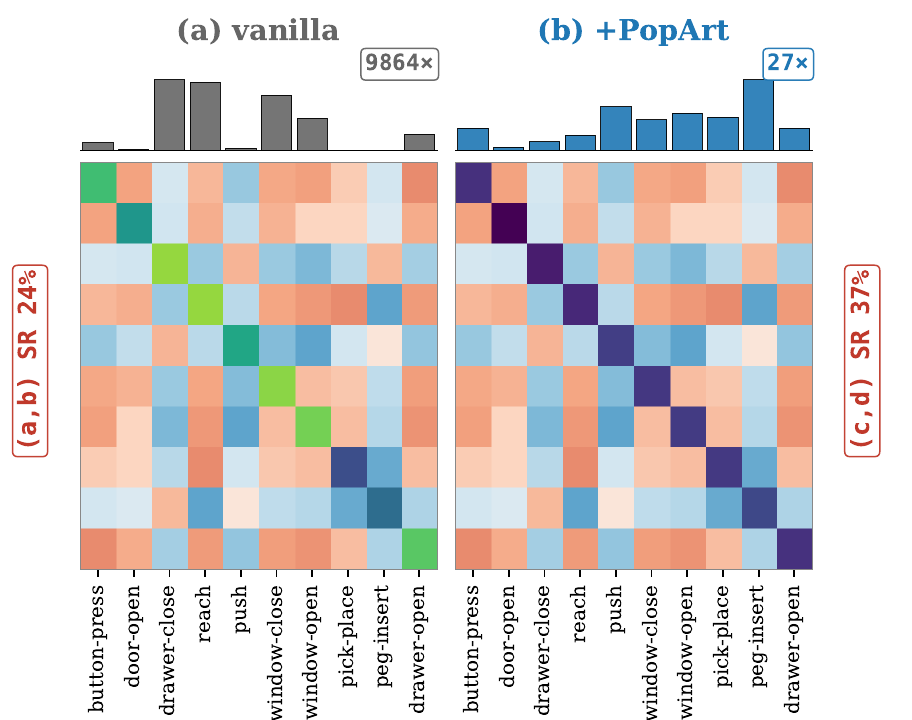
Paper Fig. 3, panels (a) vanilla and (b) +PopArt: early critic Gram diagnostics.
Layer Normalization (LN) conditions the critic features
LN-c applies pre-activation LayerNorm in the critic's hidden linear layers. It is a feature-conditioning fix, not another reward-scale normalization.
- Stabilizes hidden activation scale.
- Reduces co-linear collapse in critic gradients.
- In early MT10 diagnostics, mean off-diagonal \(|\cos|\) drops from 0.34 to 0.20.
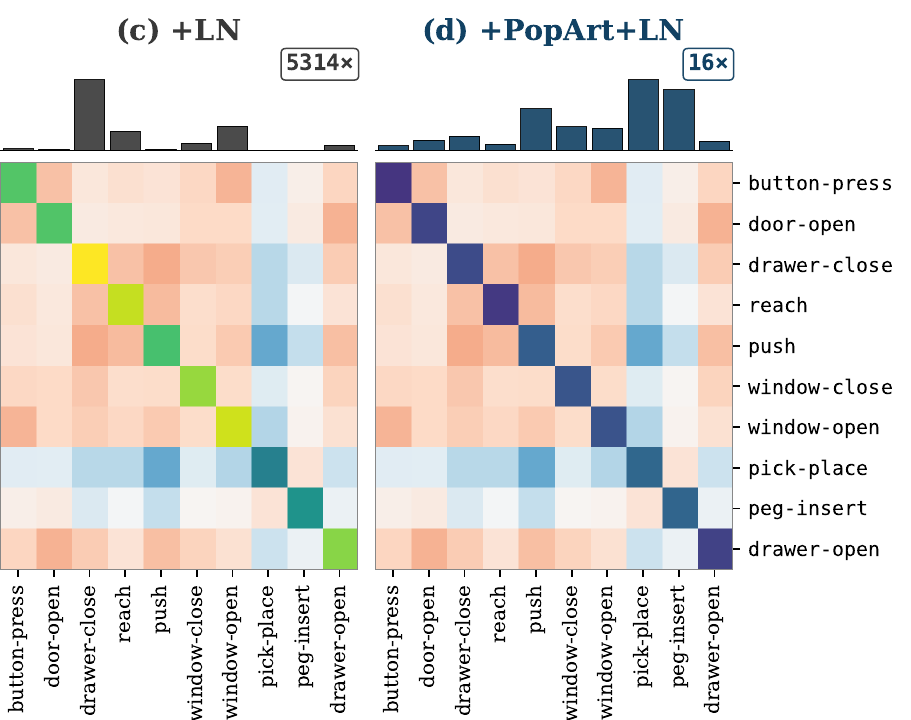
Paper Fig. 3, panels (c) +LN and (d) +PopArt+LN: cleaner diagonal and less off-diagonal collapse.
FairGrad \(\alpha=1\): fixed norm and scale invariance
Let \(G=[\langle g_i,g_j\rangle]\succ0\). If \(w>0\) solves
then the aggregate has fixed norm
For any task rescaling \(\tilde g_i=c_i g_i\), \(c_i>0\), the weights transform as \(\tilde w_i=w_i/c_i\), so \(\sum_i \tilde w_i\tilde g_i=d\).
Paper Fig. 3 panel (a): the raw critic Gram matrix shows the scale problem that FairGrad is designed to neutralize.
TOPPO recovers mean and tail performance
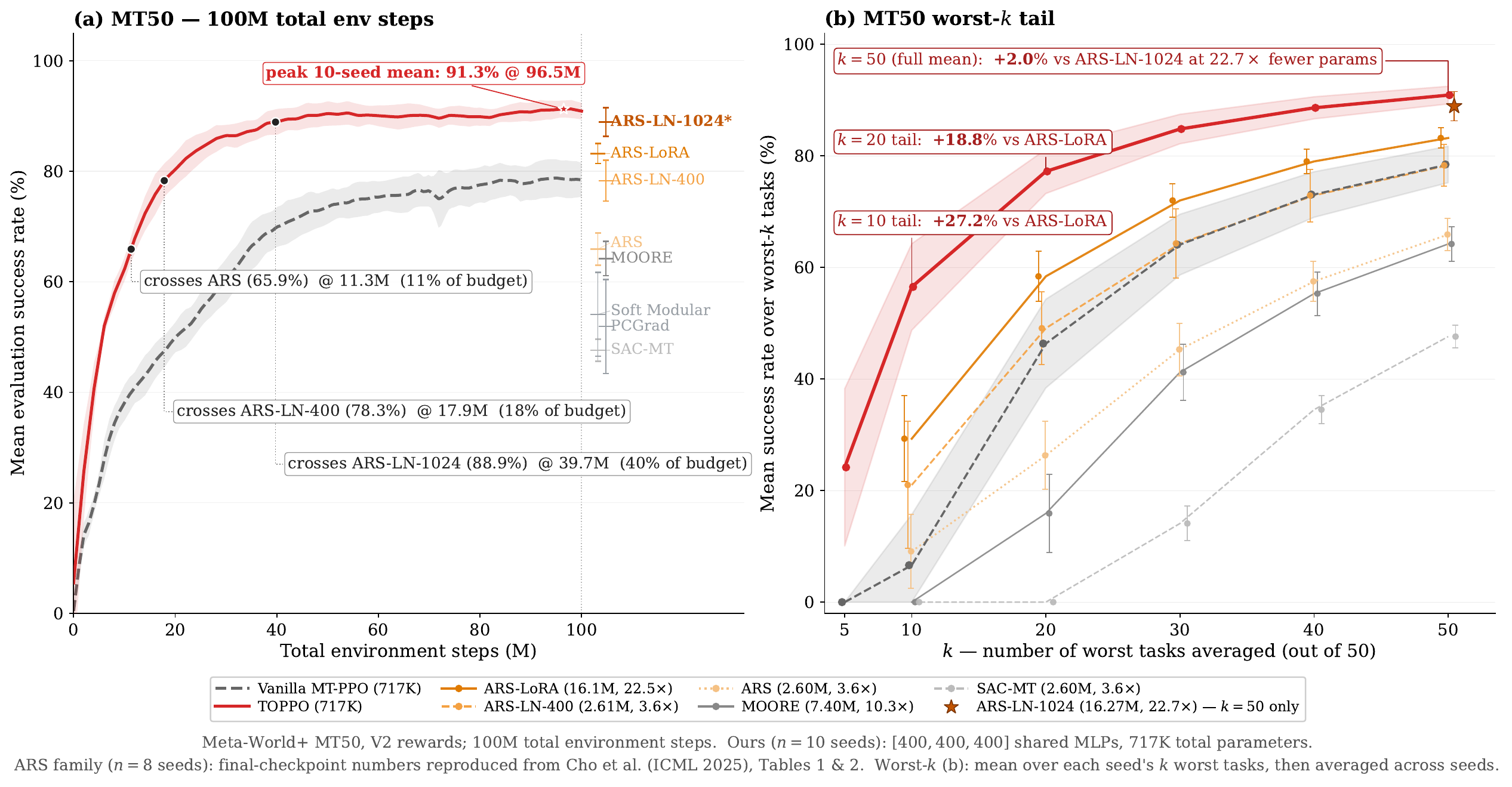
MT50 mean success
worst-10 tail success
parameters
Ablation study
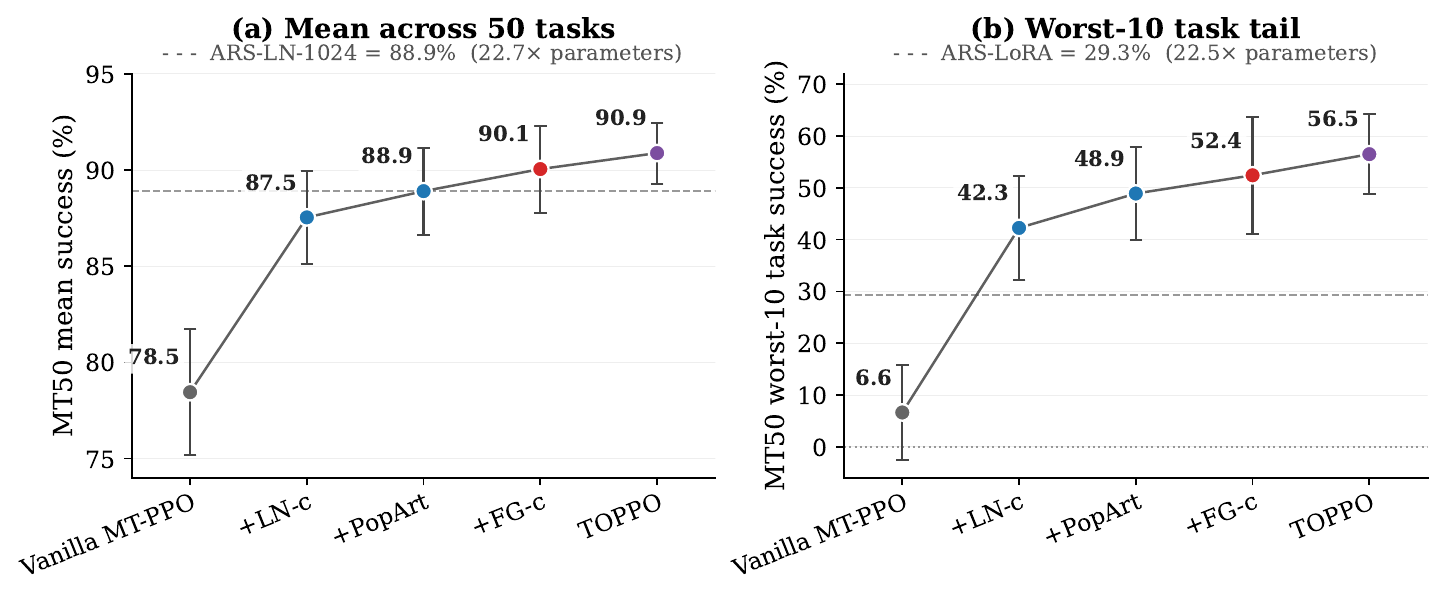
vanilla worst-10
after LN-c
TOPPO worst-10
The ladder separates the critic-side surgeries. LN-c gives the largest tail jump, while PopArt and FG-c stabilize target scale and gradient budget; the combined path matches the diagnosis before the final leaderboard comparison.